AI-technologie van de Universiteit van Washington laat dragers van een koptelefoon specifieke geluiden kiezen om te horen

Een team onder leiding van computerwetenschappers van de Universiteit van Washington (UofW) heeft AI-software voor koptelefoons gemaakt waarmee dragers specifieke geluiden kunnen selecteren om te horen. In tegenstelling tot hoofdtelefoons met ruisonderdrukking die gewoon alles wegfilteren behalve stemmen, stelt het nieuwe neurale netwerk gebruikers in staat om specifieke geluiden te selecteren, zoals het tjilpen van een vogel.
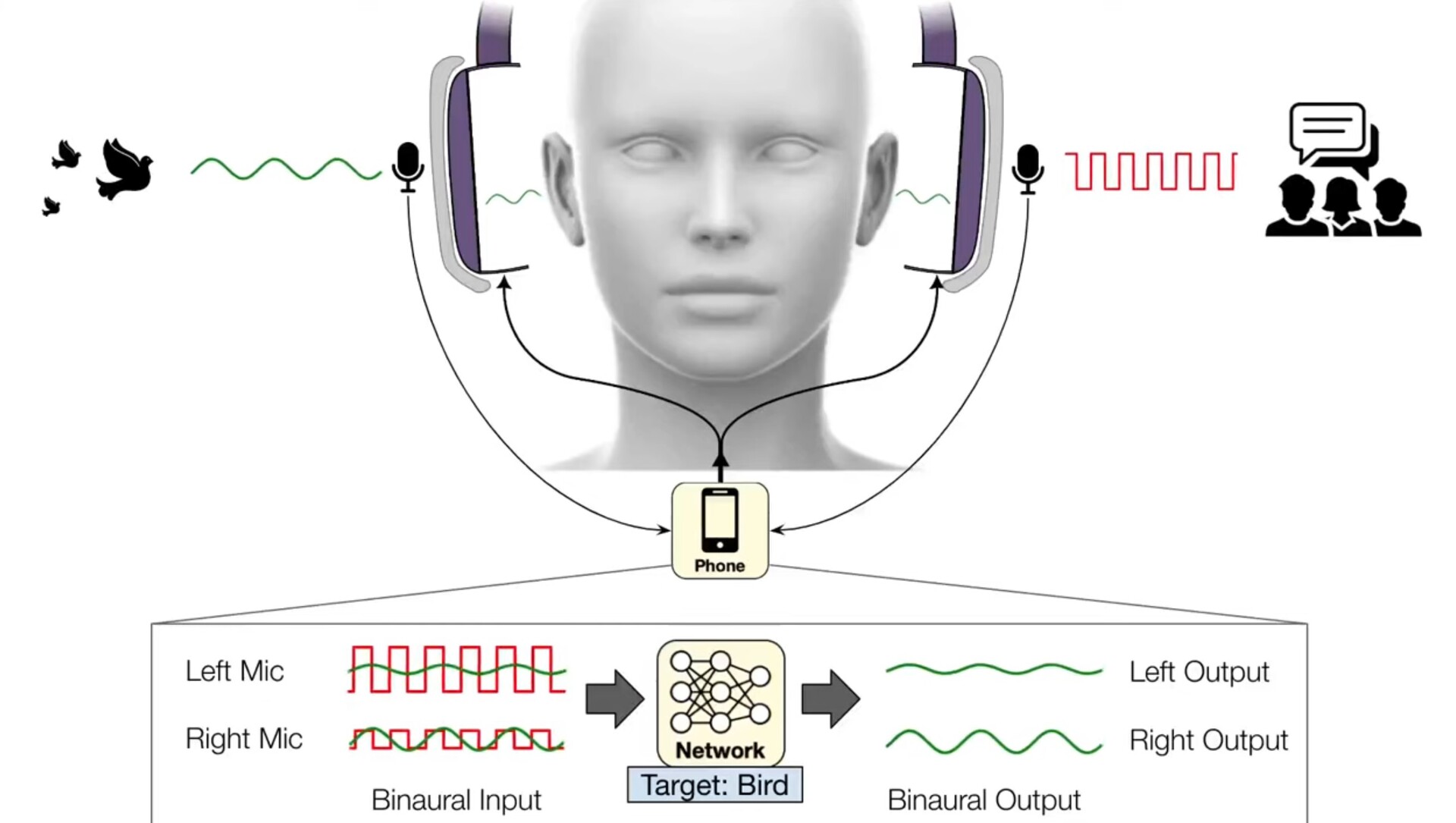
Eerdere hoofdtelefoons zoals de Sony INZONE-telefoons(verkrijgbaar bij Amazon) maken gebruik van DSEE Extreme, Speak-to-Chaten AI DNNaI-technologie om de muziek- en spraakkwaliteit te verbeteren en stemmen automatisch door ruisonderdrukking te laten gaan wanneer gesprekken beginnen. Het werk van de UofW gaat hierop verder door luisteraars in staat te stellen om te kiezen uit 20 verschillende soorten geluiden die ze willen horen, zoals het tsjilpen van vogels, de oceaan, kloppen op de deur en doorspoelen van het toilet, terwijl alle andere geluiden worden weggefilterd. Dit wordt semantisch horen genoemd en stelt gebruikers in staat om te genieten van het getjilp van vogels in een park zonder dat ze mensen horen praten of auto's voorbij horen rijden.
Op dit moment gebruikt de UofW-app binaurale microfoons om de real-time positie van externe geluiden op te vangen voordat ze gefilterde geluiden naar de hoofdtelefoon sturen. Omdat deze software op smartphones draait, kan hun app gebruik maken van krachtigere CPU's dan in hoofdtelefoons te vinden zijn, maar het is slechts een kwestie van tijd voordat hoofdtelefoons met ruisonderdrukking worden geleverd met ingebouwd semantisch horen.


Bron(nen)
Universiteit van Washington, ACM, en Paul G. Allen School (YouTube)
9 november 2023
Nieuwe AI-technologie voor ruisonderdrukkende hoofdtelefoons laat dragers kiezen welke geluiden ze horen
Stefan Milne
UW Nieuws
Iedereen die wel eens een ruisonderdrukkende koptelefoon heeft gebruikt, weet dat het van vitaal belang kan zijn om het juiste geluid op het juiste moment te horen. Iemand wil misschien autoclaxons uitwissen als hij binnenshuis werkt, maar niet als hij door drukke straten loopt. Toch kunnen mensen niet kiezen welke geluiden hun koptelefoon onderdrukt.
Nu heeft een team onder leiding van onderzoekers van de Universiteit van Washington diep lerende algoritmen ontwikkeld waarmee gebruikers in realtime kunnen kiezen welke geluiden door hun koptelefoon worden gefilterd. Het team noemt het systeem "semantisch horen" De koptelefoon streamt opgevangen audio naar een aangesloten smartphone, die alle omgevingsgeluiden onderdrukt. Via spraakopdrachten of een smartphone-app kunnen dragers van de koptelefoon kiezen welke geluiden ze willen opnemen uit 20 klassen, zoals sirenes, babygehuil, spraak, stofzuigers en vogelgetjilp. Alleen de geselecteerde geluiden worden door de hoofdtelefoon afgespeeld.
Het team presenteerde zijn bevindingen 1 november op UIST '23 in San Francisco. De onderzoekers zijn van plan om in de toekomst een commerciële versie van het systeem uit te brengen.
"Begrijpen hoe een vogel klinkt en dit uit alle andere geluiden in een omgeving halen, vereist real-time intelligentie die de huidige hoofdtelefoons met ruisonderdrukking nog niet hebben bereikt," zei hoofdauteur Shyam Gollakota, een UW-professor aan de Paul G. Allen School of Computer Science & Engineering. "De uitdaging is dat de geluiden die dragers van een koptelefoon horen synchroon moeten lopen met hun visuele zintuigen. U kunt niet iemands stem horen twee seconden nadat hij tegen u praat. Dit betekent dat de neurale algoritmen geluiden in minder dan een honderdste van een seconde moeten verwerken."
Vanwege deze tijdsdruk moet het semantische hoorsysteem geluiden verwerken op een apparaat zoals een aangesloten smartphone, in plaats van op robuustere cloudservers. Omdat geluiden uit verschillende richtingen op verschillende tijden in de oren van mensen aankomen, moet het systeem deze vertragingen en andere ruimtelijke aanwijzingen behouden, zodat mensen geluiden in hun omgeving nog steeds op een zinvolle manier kunnen waarnemen.
Het systeem werd getest in omgevingen zoals kantoren, straten en parken en was in staat om sirenes, vogelgekwetter, alarmen en andere doelgeluiden op te vangen, terwijl alle andere geluiden uit de echte wereld werden verwijderd. Toen 22 deelnemers de audio-uitvoer van het systeem voor het doelgeluid beoordeelden, zeiden ze dat de kwaliteit gemiddeld verbeterde in vergelijking met de originele opname. In sommige gevallen had het systeem moeite om onderscheid te maken tussen geluiden die veel eigenschappen gemeen hebben, zoals vocale muziek en menselijke spraak. De onderzoekers merken op dat het trainen van de modellen op meer gegevens uit de echte wereld deze resultaten zou kunnen verbeteren.
Andere coauteurs van de paper waren Bandhav Veluri en Malek Itani, beiden UW-promovendi aan de Allen School; Justin Chan, die dit onderzoek voltooide als promovendus aan de Allen School en nu aan de Carnegie Mellon University werkt; en Takuya Yoshioka, onderzoeksdirecteur bij AssemblyAI.
Neem voor meer informatie contact op met [email protected].

