Nvidia RTX 5090 draait op macOS met nieuw aangepast stuurprogramma van Tiny Corp

Apple en Nvidia beëindigden hun samenwerking vele jaren geleden, waardoor Mac-gebruikers verstoken bleven van officiële GPU-ondersteuning. Deze mislukking betekende de doodsteek voor CUDA op het platform en dwong ontwikkelaars en onderzoekers te kiezen voor Apple 's eigen Metal framework. Een nieuw open-source stuurprogramma van Tiny Corp heeft dat eindelijk opgelost door Nvidia Blackwell-hardware terug te brengen in het macOS-ecosysteem.
Het project gebruikt een aangepaste kerneluitbreiding met de naam Tiny GPU. Hiermee kunnen externe GPU's, zoals de RTX 5090, via Thunderbolt 5 of USB4 rechtstreeks communiceren met Apple Silicon Macs. Dit is op zichzelf al een grote technische sprong, omdat er helemaal geen virtuele machines nodig zijn. In de demo van Alex Ziskind wordt een RTX 5090 met 32 GB VRAM met succes gekoppeld aan een Mac Mini M4 Pro (momenteel. $1399 op Amazon voor de 24 GB/512 GB variant, hier is onze gedetailleerde review).
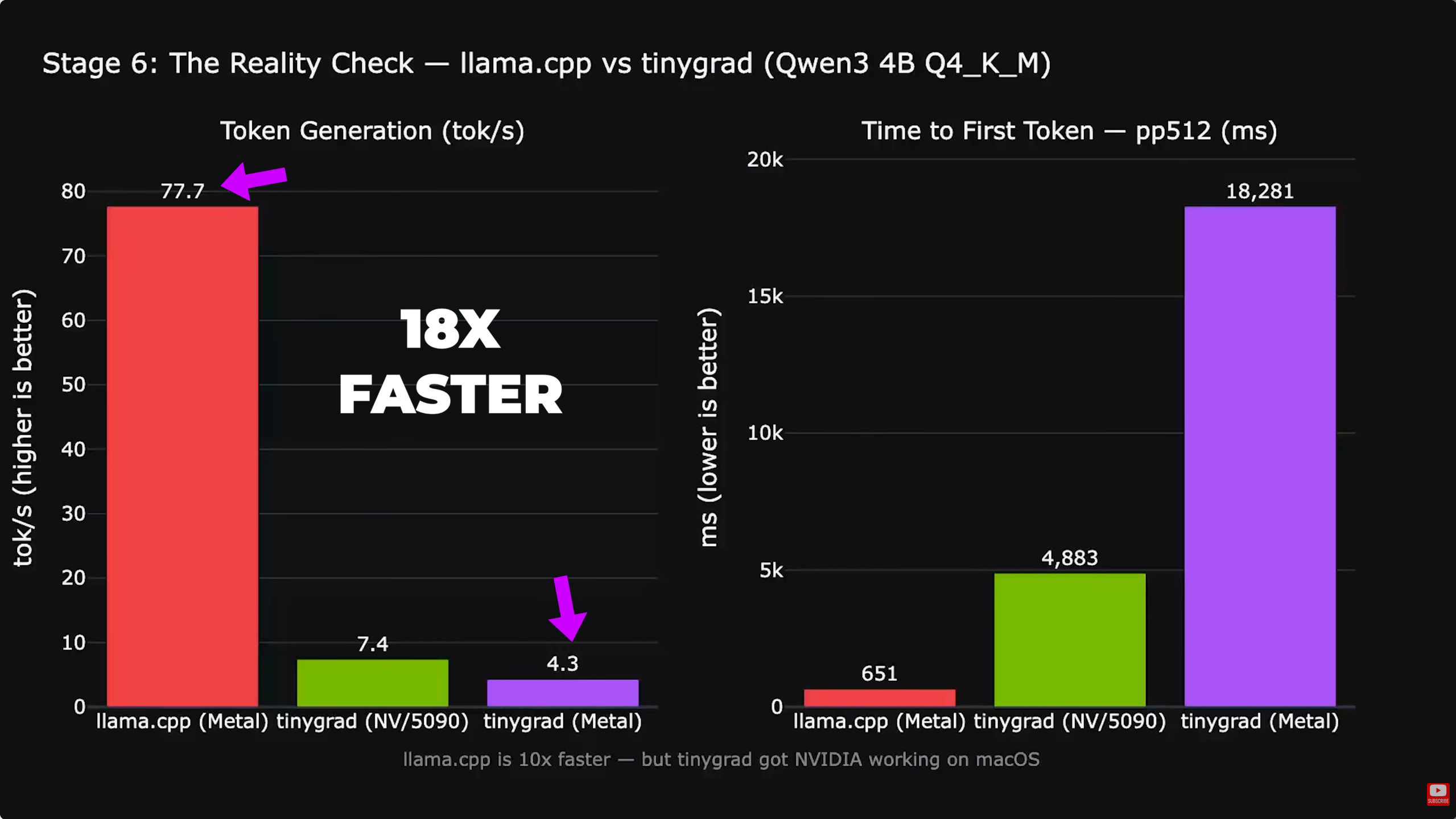
Hoewel de verbinding stabiel is, bevindt de huidige softwarestack zich in een vroeg stadium. Het stuurprogramma vertrouwt op de Tiny Grad compiler in plaats van op eigen Metal of CUDA optimalisaties. Dit zorgt voor een prestatiegat tijdens zware rekentaken. Bij het uitvoeren van het Llama 3.1 8B modelbereikte de opstelling ruwweg 7,48 tokens per seconde. Hoewel dit een grote winst is voor de compatibiliteit, is het nog steeds langzamer dan native Llama CPP op Metal, zegt Alex, dat bijna tien keer sneller is op gelijkwaardige hardware.
Hoe dan ook, de echte waarde van dit project is het potentieel voor toekomstige optimalisatie. De huidige bottleneck is niet de Thunderbolt 5 kabel, die de overdracht van modelgewicht efficiënt afhandelt, maar de efficiëntie van de automatisch gegenereerde kernels. Voor eenvoudige chatinterfaces is de Blackwell installatie snel, met snelheden van drie tot vier keer sneller dan native Metal oplossingen.
Het installatieproces omvat de goedkeuring van een systeemuitbreiding en het uitvoeren van een Docker-gebaseerde compiler pipeline. Het is duidelijk dat het (nog) geen vervanging is voor gestroomlijnde Metal workflows, maar het is wel de eerste functionele in jaren.
Bron(nen)

