CheckMag | Geen GPU, geen probleem. Uw eigen LLM hosten is oneindig veel leuker dan de gecensureerde aanbiedingen van de grote spelers en werkt verrassend goed.

Wat er eigenlijk met uw gegevens gebeurt wanneer u een AI raadpleegt, is voor iedereen een raadsel, maar wat er ook mee gebeurt, het is in ieder geval niet meer van u.
Naast afbeelding en video's, als u graag wilt experimenteren met Large Language Models (LLM), maar uw gegevens niet aan grote bedrijven wilt geven, is het hosten van uw eigen gegevens verrassend eenvoudig en heeft het verschillende voordelen ten opzichte van de grote spelers.
Wat u er ook mee doet, al uw gegevens blijven onder uw controle, wat, als u uw gegevens niet graag aan Mechahitler overhandigt, meteen een pluspunt iseen direct pluspunt is. U kunt ook vrijwel elk model gebruiken dat u maar wilt, of het nu Deepseek, Gemma2 of GPT is, met als bijkomend voordeel dat u versies kunt gebruiken die geen beperkingen opleggen aan de soorten queries die u erin gooit.
KoboldCPP is een eenvoudig te gebruiken, single-executable AI-tekstgeneratietool, ontworpen om GGUF en GGML Large Language Models uit te voeren. Het ondersteunt zowel GPU als CPU en kan fungeren als een gespecialiseerde backend voor AI-verhalen vertellen en chatten. KoboldCPP kan gedownload worden van GitHub hier en is beschikbaar voor Windows, Linux, Mac of Docker.
Hosten in een container maakt het triviaal om de LLM bloot te stellen aan elk apparaat op uw netwerk, en er zijn kant-en-klare sjablonen voor de belangrijkste platformen, waaronder Unraid en TrueNAS. Hetzelfde kan bereikt worden met andere installaties, zolang u maar de nodige regels aan uw firewall toevoegt.
Aan de slag
Zodra u hebt besloten welk platform u wilt gebruiken, moet u uitzoeken welk model u wilt gebruiken. Hugging Face is de beste plek om modellen te zoeken, en ze moeten in GGUF-formaat zijn.
Als u van plan bent om D&D-scenario's te hosten, dan wilt u absoluut een ongecensureerd model, anders zal de LLM uiteindelijk weigeren om de personages schade toe te brengen, en kan ongewenste resultaten genereren.
Sommige modellen, zoals Deepseek en Claudehebben de neiging om te "denken", waardoor in feite het hele denkproces van uw query wordt uitgespuwd. Dit kan goed gaan met een GPU die het zware werk doet, maar zonder GPU wordt het proces aanzienlijk vertraagd. U zult met modellen moeten experimenteren om er een te vinden die voor u werkt, maar Gemma2 is een goede plek om te beginnen.
Zoek de bestandenpagina en kopieer de URL die naar het GGUF-bestand linkt. Veel modellen hebben meerdere groottes, dus u zult er een moeten kiezen die past binnen de beperkingen van uw beschikbare RAM.
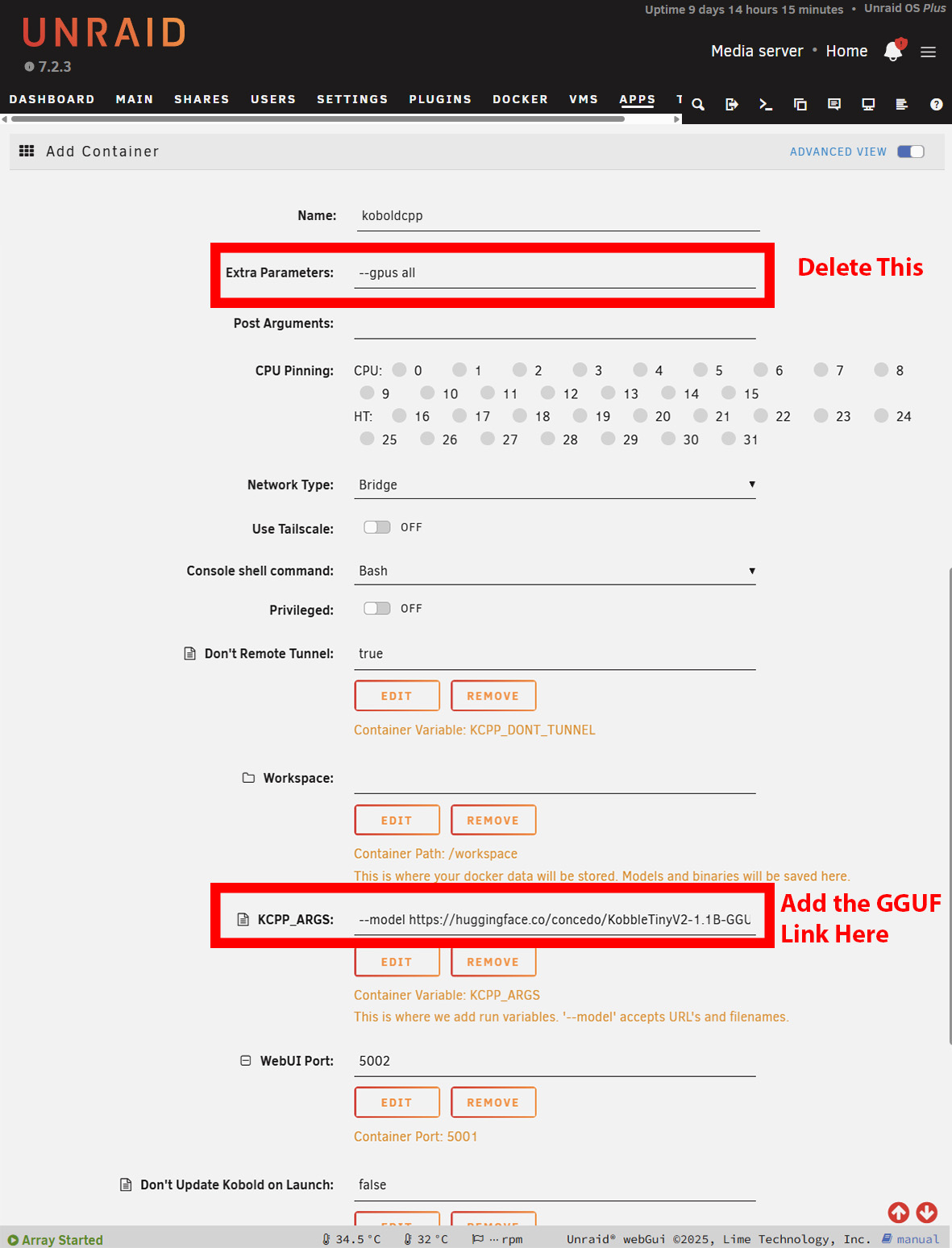
De installatie onder Windows is grotendeels hetzelfde. U moet echter de NoCUDA versie downloaden als u zonder GPU gebruikt. Het kan even duren voordat het opstart, omdat KoboldCPP het model downloadt voordat u de interface te zien krijgt. Op Windows is dit vanzelfsprekend, maar op Unraid of TrueNAS moet u de logs openen om de voortgang van de download te zien. Op Unraid moet u misschien verhogen om de beschikbare opslagruimte van de Docker-containers te vergroten de beschikbare opslagruimte van de Docker-containers vergroten, afhankelijk van hoe groot het door u gekozen model is.
KoboldCPP biedt 4 verschillende interfacemodi, waaronder instructie, verhaal, chat en avontuur.
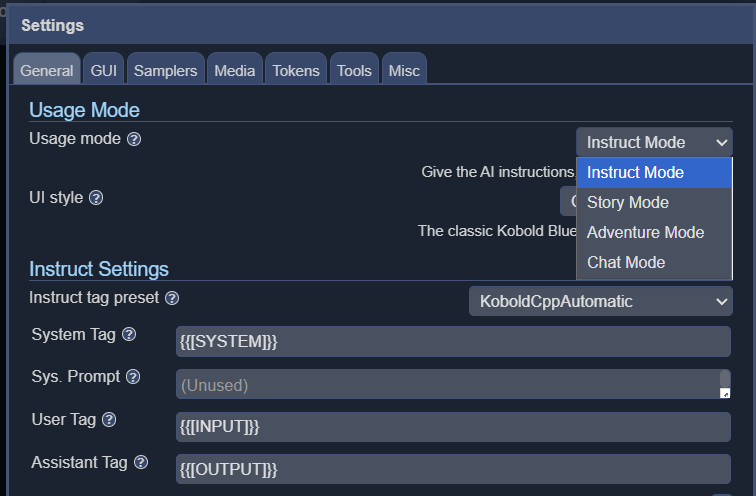
Hoewel het bij lange na niet de snelste is, wordt tekst iets langzamer gegenereerd dan de gemiddelde leessnelheid. Het is perfect bruikbaar voor D&D scenario's op een 16-core AMD 5950x(verkrijgbaar bij Amazon) en zal waarschijnlijk sneller werken op modernere CPU's. Hoe meer cores u kunt gebruiken, hoe beter, en met een behoorlijke hoeveelheid RAM-geheugen kunt u grotere modellen draaien, hoewel u met 16GB al goed uit de voeten kunt. De grootte en het type van het model hebben ook een grote invloed op de generatorsnelheid, en door een lichter model te kiezen kunt u de algehele snelheid aanzienlijk verhogen.
Voor de beste ervaring is het natuurlijk optimaal om Grote Taalmodellen met een GPU te draaien, maar als u graag uw eigen hosting wilt proberen, om de beperkingen of gegevensprivacyimplicaties van ChatGPT, Claude of Gemini te omzeilen, hebt u geen dure hardware nodig om aan de slag te gaan en kunt u nog steeds een fatsoenlijke ervaring krijgen.
Bron(nen)

