Een verrassende taal verslaat Engels en Chinees in LLM-tests, volgens nieuw academisch onderzoek
Een nieuwe meertalige studie die evalueert hoe grote taalmodellen omgaan met lange documenten heeft een onverwacht stukje informatie opgeleverd: Pools, niet Engels of Chinees, vertoont de hoogste nauwkeurigheid wanneer contextvensters zich uitstrekken tot 64.000 tokens en meer. De bevindingen zijn afkomstig van de OneRuler benchmark die werd geïntroduceerd in een COLM 2025 paperwaarin 26 talen werden getest voor opzoek- en aggregatietaken.
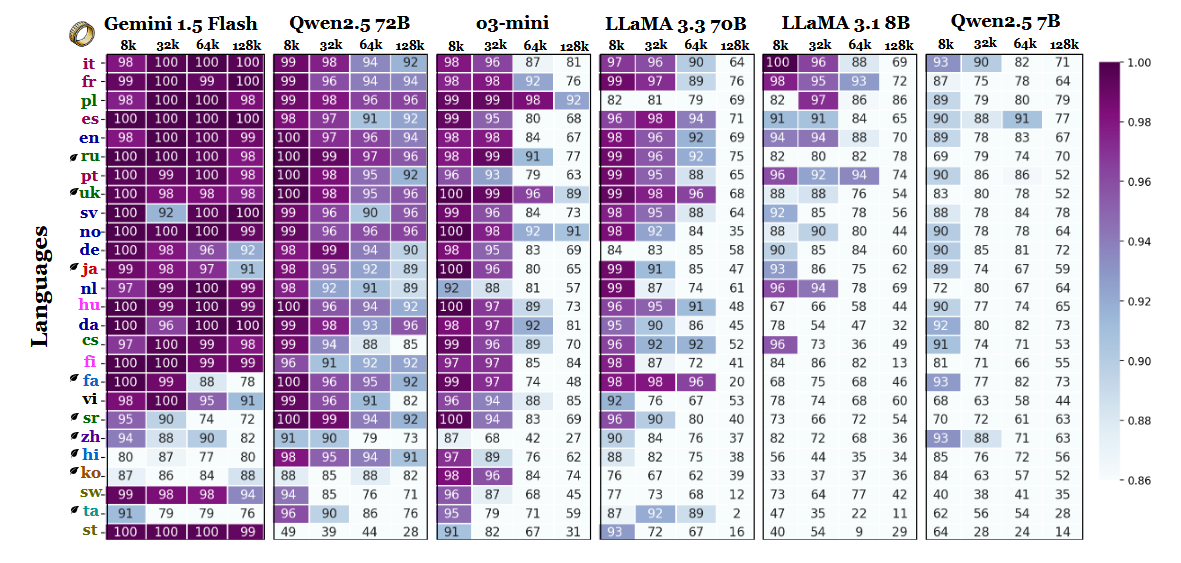
De onderzoekers vergeleken de modelnauwkeurigheid bij meerdere contextlengtes en vonden een duidelijke verschuiving zodra de reeksen langer werden. Volgens de resultatentabel (op pagina 6) leidt het Pools alle talen met een gemiddelde nauwkeurigheid van 88% bij lange contextlengtes. Het Engels zakt naar de zesde plaats en het Chinees staat in de onderste vier.
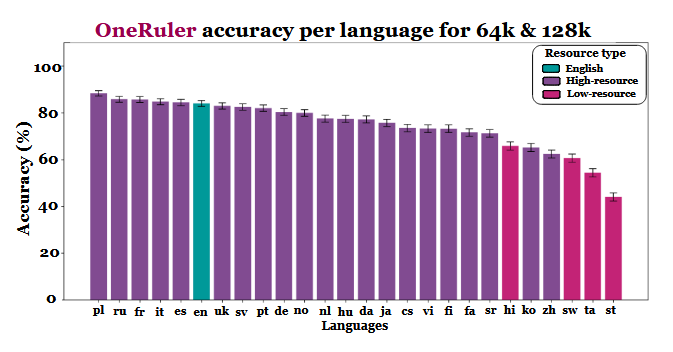
De studie laat doorschemeren dat het verschil mogelijk eerder te maken heeft met tokenization-efficiëntie en verschillen in scripts dan met het volume van de trainingsgegevens. Talen die Latijnse schriften gebruiken - zoals Pools, Frans en Spaans - presteerden consequent beter dan talen die logografische of abugida-schrijfsystemen gebruiken. Chinees, Koreaans, Tamil en andere talen vertoonden zelfs bij kortere contexten slechts een matige nauwkeurigheid (en hun nauwkeurigheid ging nog verder achteruit naarmate de reeksen langer werden). Deze volledige 180 van de verwachte rangschikking is interessant, omdat de meeste op grote schaal gebruikte LLM's voornamelijk zijn getraind op datasets die veel Engels gebruiken. Toch geven de resultaten van de paper aan dat zodra modellen informatie moeten zoeken, terughalen of samenvatten die diep in lange documenten begraven ligt, structurele aspecten van de taal de voorkeur krijgen boven de prevalentie van de dataset.
Andere bevindingen in de benchmark ondersteunen deze interpretatie ook. De prestatiekloof tussen de sterkste en zwakste talen groeit sterk naarmate de context groter wordt - van 11% bij 8.000 tokens tot 34% bij 128.000 tokens. Een ander detail uit het onderzoek laat zien hoe gevoelig deze tests kunnen zijn voor kleine instructiewijzigingen. Door het model bijvoorbeeld toe te staan "none" te antwoorden als een doelstring afwezig is, daalde de nauwkeurigheid in het Engels met 32% bij 128k tokens, zoals te zien is op pagina 2.
Hoewel de benchmark ook modelfamilies vergelijkt, impliceren de resultaten dat evaluatie van lange contexten niet alleen op Engelse tests kan vertrouwen en dat generalisaties van prestaties tussen talen misleidend kunnen zijn als script- en tokenization-effecten worden genegeerd. Naarmate contextvensters groter worden, worden taalverschillen belangrijker, niet minder - en de dominantie van het Engels in LLM benchmarks is mogelijk niet langer representatief zodra de sequentielengte in de tienduizenden loopt.
Bron(nen)
Eén meetlat voor alles: Meertalige taalmodellen met lange contexten benchmarken bij COLM 2025
Aanbevolen afbeelding door Zulfugar Karimov op Unsplash

